FreEMnorm¶
FreEMnorm is a parallel corpus covering a range of different genres of text throughout different decades of the 17th century. It is the new version of PARALLEL17, which is now deprecated.
Publications¶
Data (GitHub and Zenodo):
- Gabay, Simon, Philippe Gambette, FreEM-corpora/FreEMnorm: FreEM norm Parallel corpus (1.0.1), GitHub, 2022. https://github.com/FreEM-corpora/FreEMnorm .
- Gabay, Simon, Philippe Gambette, FreEM-corpora/FreEMnorm: FreEM norm Parallel corpus (1.0.1), Zenodo, 2022. 10.5281/zenodo.5865428.
Conference papers:
- Simon Gabay, Marine Riguet, Loïc Barrault, "A Workflow For On The Fly Normalisation Of 17th c. French", DH2019, ADHO, Jul 2019, Utrecht, Netherlands. ⟨hal-02276150⟩.
- Simon Gabay, Loïc Barrault, "Traduction automatique pour la normalisation du français du XVIIe siècle", TALN 2020, ATALA, Jun 2020, Nancy, France. ⟨hal-02596669⟩.
- Rachel Bawden, Jonathan Poinhos, Eleni Kogkitsidou, Philippe Gambette, Benoît Sagot, Simon Gabay, "Automatic Normalisation of Early Modern French", Proceedings of the 13th Language Resources and Evaluation Conference, European Language Resources Association, Jun 2022, Marseille, France, p. 3354‑3366. ⟨hal-03540226⟩.
Content¶
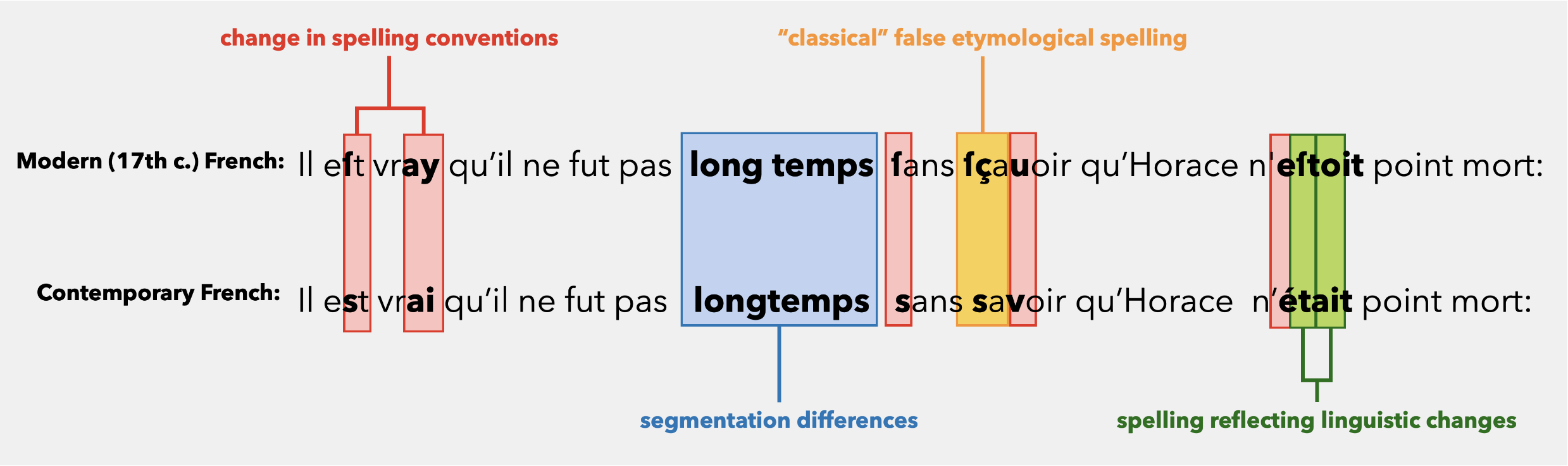
FreEMnorm is a parallel corpus covering a range of different genres of text throughout different decades of the 17th century, written in prose and verse, which have been semi-automatically normalised (Gabay 2019) and manually corrected. Most of these texts are French texts that belong to the belles-lettres (i.e. literature in its broadest sense), which is the type of source we want to normalise, but additional texts from different traditions (science, law, etc.) are marginally present in the corpus.
While some of the transcriptions have been produced specifically for this corpus, others have been borrowed from other projects: transcription rules are therefore not strictly equivalent from one text to another regarding, for instance old characters (e.g. the long s, ſ) and abbreviations (e.g. õ→on). "Normalisation" is understood here as a partial alignement with contemporary French: in some specific cases, specific spelling are maintained to keep the metre of the verse intact (e.g. the adverbial -s: jusques+vowel → jusques and not jusqu' to keep its three syllables).
The dataset is split into train, development and test sets, of which basic statistics are as follows:
| Set | #sents | #ModFr toks | #Fr toks | #ModFr OOV* | #Fr OOV* toks |
|---|---|---|---|---|---|
| Train | 17,930 | 264,311 | 263,669 | - | - |
| Dev | 2,443 | 40,435 | 40,294 | 1,766 | 1,312 |
| Test | 5,706 | 86,432 | 86,211 | 3,596 | 2,530 |
* OOV stands for out-of-vocabulary
The detailed content of the repository is available on GitHub.