FreEMmax¶
Usable historical texts are difficult to find because they are more rare than contemporary ones, editors tend to normalise the language (i.e. use the spelling conventions of contemporary French), transcriptions are not (always) distributed in a digital format. FreEMmax is an attempt to solve this problem: the aim of this dataset is to group together the largest number or texts possible written in Early Modern French.
Because not all sources are open, FreEMmax comes two versions: one is restricted, one is open access.
Publications¶
Data (GitHub and Zenodo):
- Gabay, Simon, Bartz, Alexandre, Gambette, Philippe, & Chagué, Alix, FreEM-corpora/FreEMmax_OA: FreEM max OA: A Large Corpus for Early modern French - Open access version (1.0.0), GitHub, 2022. https://github.com/FreEM-corpora/FreEMmax_OA.
- Gabay, Simon, Bartz, Alexandre, Gambette, Philippe, & Chagué, Alix, FreEM-corpora/FreEMmax_OA: FreEM max OA: A Large Corpus for Early modern French - Open access version (1.0.0), Zenodo, 2022. 10.5281/zenodo.6481135.
Conference paper:
- Simon Gabay, Pedro Ortiz Suarez, Alexandre Bartz, Alix Chagué, Rachel Bawden, et al.. "From FreEM to D'AlemBERT: a Large Corpus and a Language Model for Early Modern French", Proceedings of the 13th Language Resources and Evaluation Conference, European Language Resources Association, Jun 2022, Marseille, France. ⟨hal-03596653⟩.
Sources¶
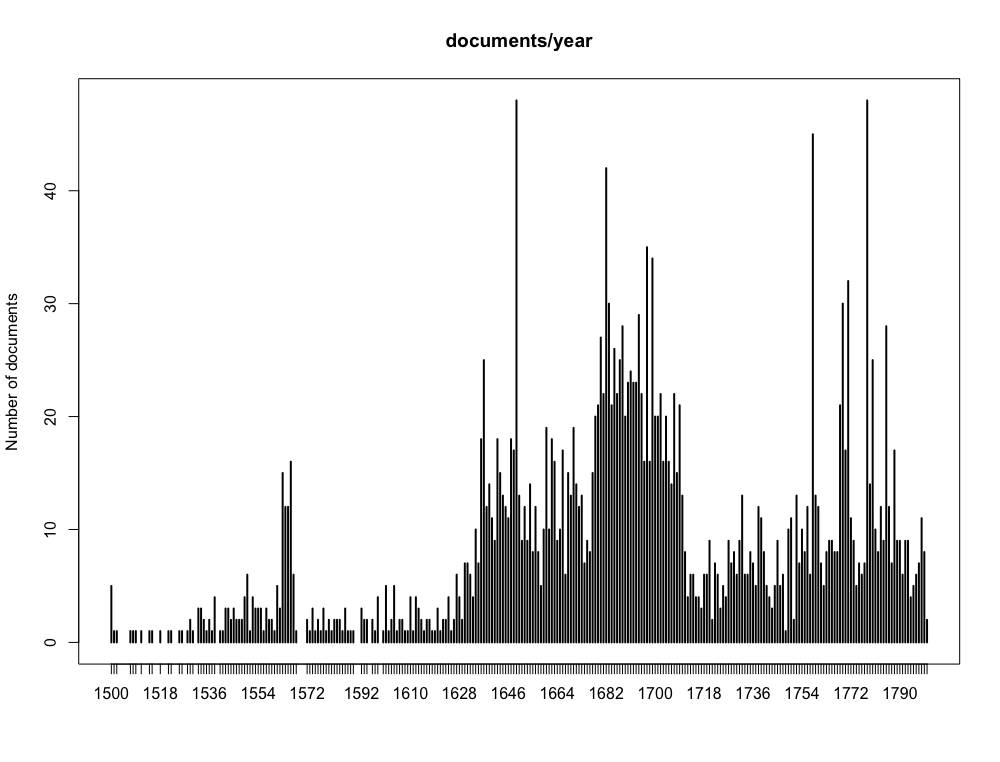
The texts have a variety of sources, which can be grouped into three main types:
-
Two institutional datasets have been used and are non open-sourced:
- FRANTEXT intégral, the biggest database of French texts (only the texts between 1500 and 1800), a very small portion of which is open access: FRANTEXT Démonstration;
- Electronic Enlightenment an online collection of edited correspondences of the Early Modern period;
-
Several come from research projects distributing transcriptions online:
- The Antonomaz project, French mazarinades (https://cahier.hypotheses.org/antonomaz, https://github.com/Antonomaz) ;
- The II.B section (in French) of the Actis Pacis Westphalicae, diplomatic letters for the Peace of Westphalia (http://kaskade.dwds.de/dstar/apwcf/) ;
- The Bibliothèques virtuelles humanistes, 16th c. French literature (http://www.bvh.univ-tours.fr) ;
- The Corpus électronique de la première modernité, 17th c. French literature (http://www.cepm.paris-sorbonne.fr) ;
- The Condé project, coutumiers normands (https://conde.hypotheses.org)
- The Corpus Descartes, works of René Descartes (https://www.unicaen.fr/puc/sources/prodescartes/) ;
- The Bibliothèque dramatique of the CELLF, 17th c. French plays (http://bibdramatique.huma-num.fr) ;
- The Fabula numerica project, French fables (https://obvil.sorbonne-universite.fr/projets/fabula-numerica) ;
- The Fonds Boissy, plays of Louis de Boissy (https://www.licorn-research.fr/Boissy.html) ;
- The Mercure Galant project, the famous French gazette and literary magazine between 1672 and 1710 (https://obvil.sorbonne-universite.fr/corpus/mercure-galant) ;
- The Rousseau online project, works of Jean-Jacques Rousseau (https://www.rousseauonline.ch) ;
- The Sermo project, sermons of the 16th and 17th c. (http://sermo.unine.ch);
- The Théâtre classique project, 17th and 18th c. French plays (http://www.theatre-classique.fr) ;
-
Additional sources come from researchers who kindly accepted to offer their personal transcriptions or data scrapped by our team:
- Transcriptions of Anne-Elisabeth Spica (17th c. French novels);
- Transcriptions found on Wikisource (https://fr.wikisource.org) ;
- Transcriptions (ePub files) found on Gallica (https://gallica.bnf.fr) ;
- Transcriptions found on various websites online
Building the corpus¶
For legal reasons, it is impossible to distribute some TEI files that require modifications.
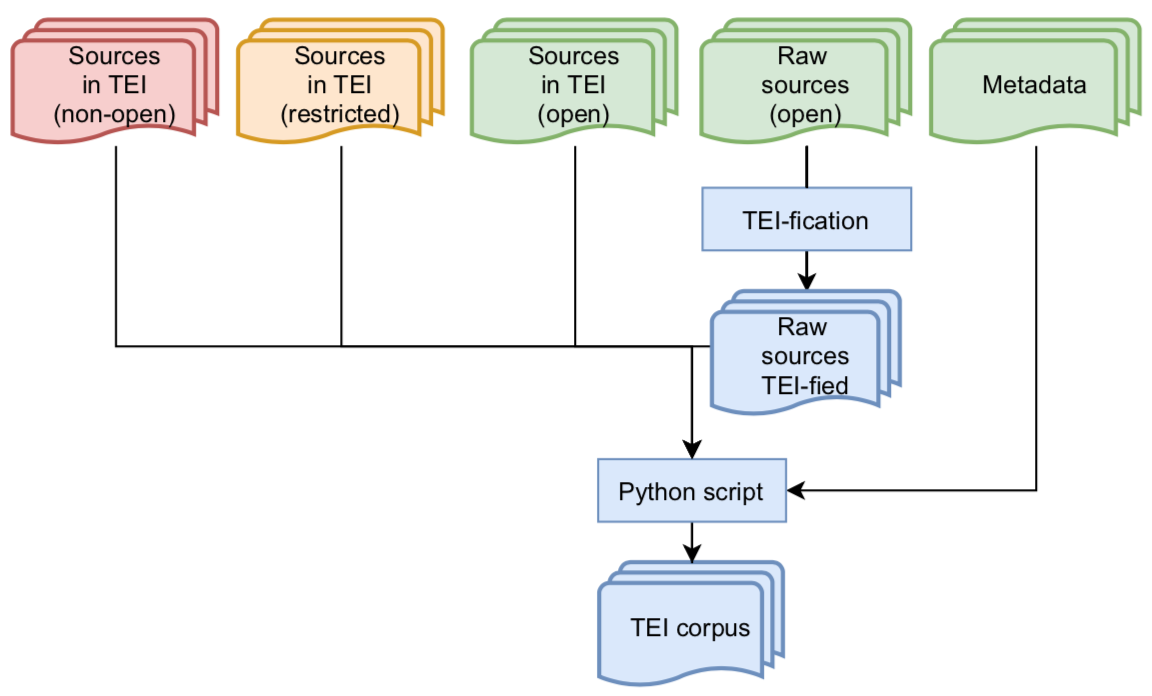
All files are kept in their original format. Metadata is manually prepared in separate files in order to automatically transform and clean (in blue) all the available documents into XML TEI files following the same encoding. It allows us to distribute open data (in green) but also data distributed with restrictions regarding the modification of the original format (in orange). Non-open texts (in red) are not distributed.